Tuning PID Controllers with Automatic Differentiation
PID controllers are the workhorses of industrial control. They are simple enough to fit on a microcontroller, yet surprisingly effective across a wide range of systems. The catch is that tuning them well takes time and, if you are being honest, a fair amount of intuition. Classic recipes like Ziegler-Nichols are fast but often leave performance on the table. Model-free autotuning approaches work but can require live experiments on the real plant.
Here is a different take: write down a differentiable simulation of your system, define a loss that captures what “good control” means to you, and let gradient descent find the gains. Automatic differentiation handles the calculus; you just specify the objective.
This post walks through exactly that, using JAX1. The controller structure follows the practical implementation guidelines of Sundström et al.2
The Example: A Second-Order Mass-Spring-Damper
The plant is a linear mass-spring-damper:
with mass , damping , and spring stiffness . The PID controller drives the position to a unit step setpoint.
This system has a natural frequency of and a damping ratio of , so the open-loop step response is lightly damped and oscillatory — a good stress test for the tuning method.
The Incremental (Velocity) Form
Rather than computing the control output directly at each step, the simulation uses the incremental (or velocity) form: only the increment is computed, and the output is accumulated as .
This structure has several practical advantages over the position form. Actuator saturation and bumpless switching are easier to handle because the accumulator naturally keeps track of where the integrator state is. There is also no integral wind-up from the proportional or derivative paths — only the explicit integral increment can cause wind-up.
Setpoint weighting
A standard PID controller applies the setpoint equally to all three terms. In practice it is often better to split this: let the proportional and derivative paths see a weighted version of the setpoint, while the integral path always sees the full error.
Two weights and parameterise this:
Setting reduces the proportional kick when the setpoint steps, giving a smoother response without sacrificing integral action. Setting makes the derivative act only on measurement changes — eliminating the large derivative spike that would otherwise appear at when jumps discontinuously.
Derivative approximation
Rather than differentiating the error, the derivative is approximated separately for and via finite differences:
The second-difference increments and then enter the derivative increment directly.
Discrete update equations
The full incremental update at step is:
where and .
For a constant setpoint on every step after the initial one, so the proportional increment reduces to and only responds to how the output is changing. The integral term carries the absolute error information needed to eliminate steady-state offset.
The plant is integrated with semi-implicit Euler (velocity updated before position), which is slightly more stable than explicit Euler for oscillatory systems at the same step size .
Saturation and Anti-Windup
Rate-limited bounds
Rather than applying fixed saturation limits directly, the active bounds at each step are tightened by a rate constraint on the previous output :
This limits how fast the actuator output can change between steps, independently of the absolute limits. In the current simulation the rate limits are set large enough to be inactive, but the structure is in place for the general case.
Anti-windup by soft pull-back
After computing , a soft correction pulls the signal back toward the feasible region before the hard clip:
When the signal is within bounds and the correction vanishes. When saturated, the correction partially unwinds the accumulator at a rate governed by the time constant . The state carried forward is (after soft correction, before the final hard clip), so the integrator is reset smoothly rather than hard-clamped. The hard clip on ensures the plant never sees an out-of-range command.
The Loss Function
The objective combines four terms:
where and .
Weighted tracking is the dominant term. The quadratic time-weighting goes from at to at , so errors near the end of the simulation are penalised six times more than early-transient errors.
Tail penalty adds a hard push toward zero once the error exceeds . It acts as a deadband: below the threshold the gradient from this term vanishes, preventing the optimiser from over-tightening in the noise-free simulation.
Effort penalises large control signals with a small coefficient (), discouraging unnecessarily aggressive gains.
Integral penalty discourages large integral accumulation, which indirectly limits integral wind-up.
Why JAX?
JAX’s jit + grad pipeline means the gradient computation costs roughly the same as two forward passes — that is the magic of reverse-mode AD. With jax.lax.scan you can unroll the simulation loop without materialising every intermediate in Python, keeping compilation time and memory under control even for long horizons.
There are no finite-difference approximations and no symbolic manipulations. The gradients are numerically exact (up to floating point) regardless of the complexity of the integrator or the loss. Crucially, jnp.clip is differentiable in JAX: its subgradient is zero in the saturated region and one elsewhere, so the optimizer receives a correct signal even when the saturation bounds are active.
Optimisation Setup
The optimised parameters are , initialised at . The setpoint weights and are treated as fixed constants — the gradient is taken only with respect to the three gains. This decoupling is intentional: and encode a design choice about how aggressively the controller should react to setpoint steps, and are better set by the engineer than discovered by gradient descent.
Adam runs for 3000 iterations with a cosine-decaying learning rate starting at . The decay is important: without it the gains could grow indefinitely, since larger gains always reduce the time-weighted tracking error. The cosine schedule lets the optimiser move fast early and then freeze the gains as the learning rate approaches zero.
Results
Step Response Comparison
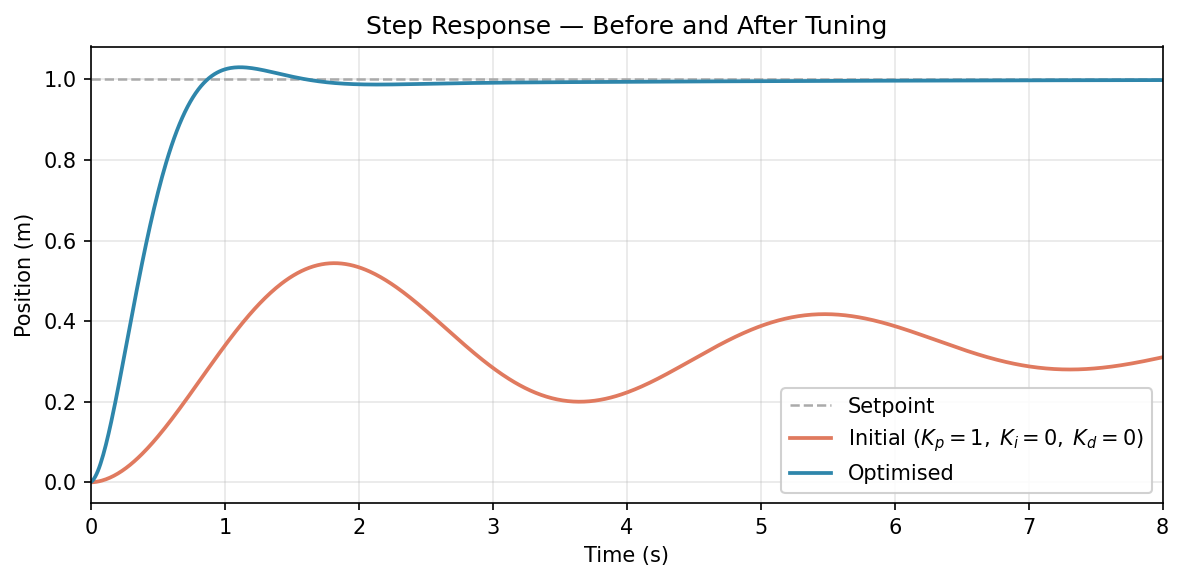
Orange is the initial controller (). With the incremental form and no integral action, the controller accumulates a small control output on the first step (proportional kick from the setpoint step) and then only reacts to changes in the output — there is no mechanism to correct the residual position error once the output stops moving, so the response plateaus well below the setpoint.
Blue is the optimised controller. Integral action is the key difference: the term keeps injecting a correction proportional to the current error, driving the output to the setpoint and holding it there.
Loss Curve
The loss drops by almost three orders of magnitude over 3000 iterations.
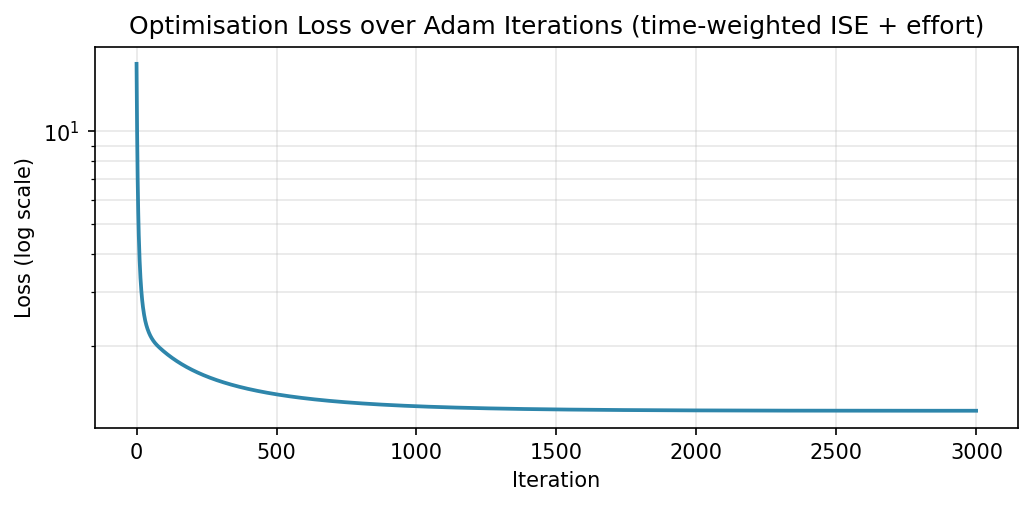
The steepest descent happens in the first few hundred iterations when the learning rate is near its peak value. After roughly iteration 1000 the cosine schedule has reduced the learning rate significantly and the curve flattens, indicating convergence.
Gain Trajectories
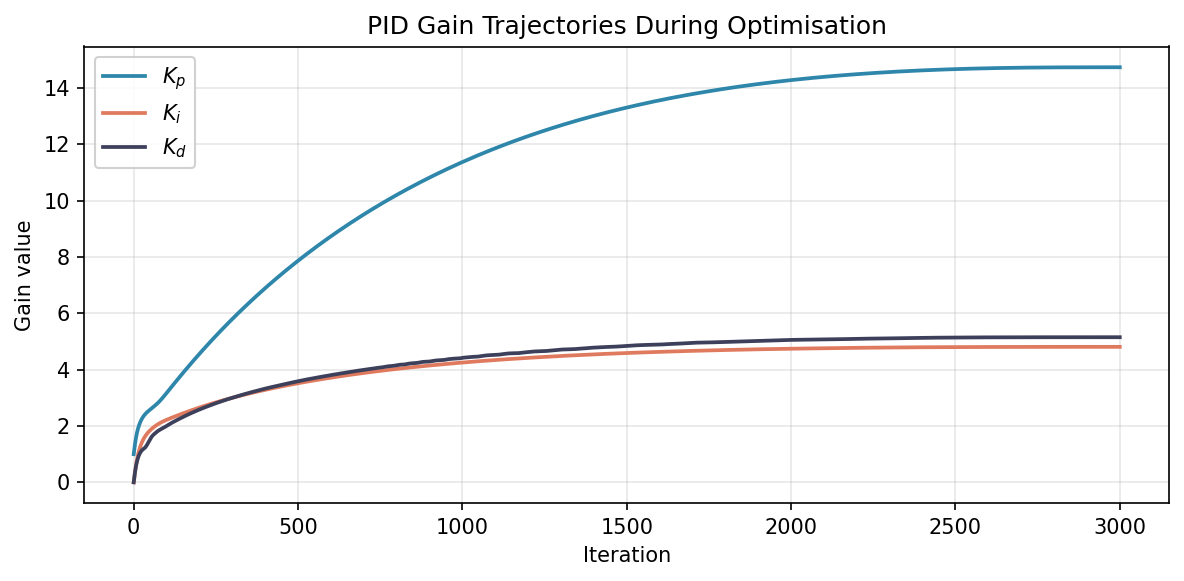
and respond immediately — they act on the current output change and its rate, so their gradient signal is strong and direct from the first step. lags because its effect accumulates over the entire trajectory; the gradient signal reaching it is more diffuse and takes longer to build up.
All three curves flatten as the cosine schedule drives the learning rate toward zero — a clean visual signature of convergence rather than a hard stop.
Tracking Error
![]()
Orange (initial, ): the error settles to a non-zero constant. In the incremental form, once the plant reaches a pseudo-equilibrium the output increments vanish () and the control signal stops changing — locking in whatever offset remains.
Blue (optimised): the error oscillates briefly during the transient then decays to zero. The integral action is the mechanism: as long as , keeps nudging the control output, and the accumulator only stops changing when the error is truly zero.
Control Effort
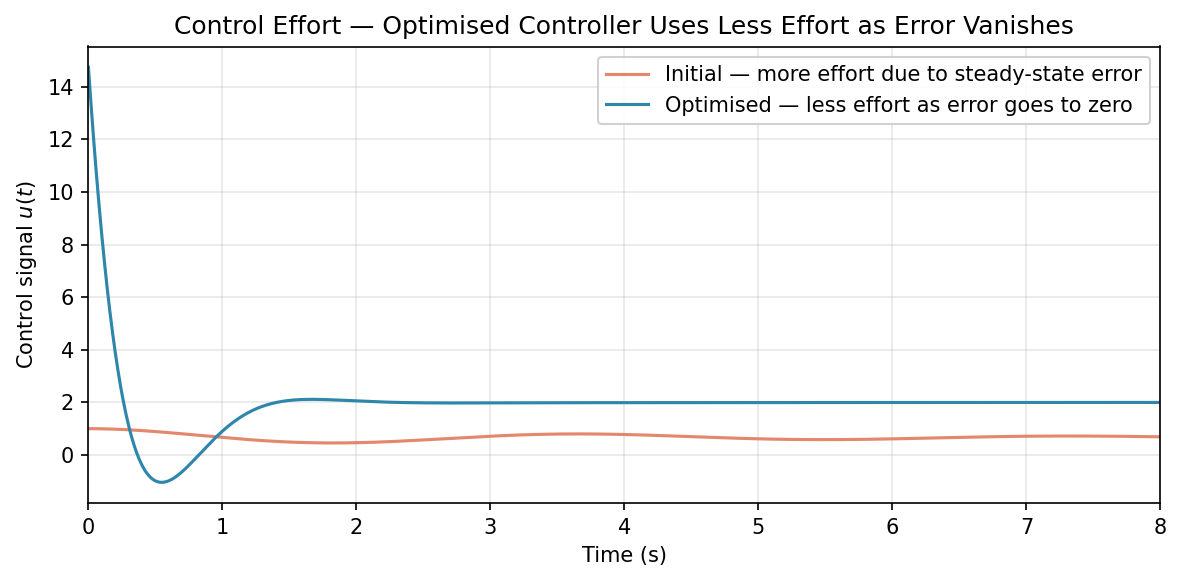
At the controller sees a step in from to : , , so . This is a finite proportional kick scaled by the setpoint weight . There is no derivative spike: since and after the first step, the derivative increment is — acting only on how the measurement is accelerating, not on the setpoint jump.
After the transient the optimised control signal settles to approximately , which is the spring force needed to hold the mass at .
Practical Considerations
Setpoint weights as design parameters. and control the trade-off between setpoint tracking aggressiveness and smooth transients. softens the proportional response to reference steps. turns the derivative into pure derivative-on-measurement, removing any setpoint-related derivative kick entirely. These are typically tuned by the engineer rather than optimised, because gradient descent can satisfy them in unintended ways (e.g. by exploiting the interaction between and ).
Anti-windup time constant. governs how quickly the integrator is unwound when the actuator saturates. A small (aggressive reset) can introduce instability if the plant is slow to respond. A value in the range to the closed-loop settling time is a common practical starting point. Here as a loose default.
Simulation fidelity. Gradient-based tuning is only as good as your model. If the simulation drifts significantly from the real plant, the optimal gains may not transfer. Sim-to-real gap is the main risk.
Numerical stability. Long rollout horizons can cause gradient magnitudes to grow or shrink exponentially — the same instability that plagues RNN training. For stiff systems or long horizons, consider a smaller step size, a more stable integrator (e.g. RK4), or gradient clipping.
Local minima. The closed-loop simulation loss is generally non-convex in the gains. In practice the basin of attraction is large for common plant types and reasonable initial guesses, but running from several starting points builds confidence.
Takeaways
- You can treat PID gain tuning as a standard gradient-based optimisation problem by differentiating through a closed-loop simulation.
- JAX makes this straightforward: write the rollout as
jax.lax.scan, define the loss, calljax.grad. - The incremental form simplifies saturation and anti-windup handling: only the integral increment accumulates wind-up, and the accumulator state is transparent.
- Setpoint weighting (, ) decouples transient aggressiveness from steady-state performance. Fixing these as design constants and optimising only the gains avoids the optimizer finding degenerate solutions.
- The soft anti-windup pull-back keeps the integrator state smooth when the actuator saturates, without the discontinuity of hard clamping the increment.
- Gradient descent discovers control structure. Starting from a P-only controller, the optimiser finds on its own that integral action is needed — because without it the time-weighted loss is unavoidably large.
The Python script used to generate all plots is available if you want to run the experiments yourself.
Footnotes
-
J. Bradbury et al., “JAX: Composable transformations of Python+NumPy programs,” version 0.3.13, 2018. [Online]. Available: http://github.com/jax-ml/jax ↩
-
E. Sundström, M. Bauer, J. L. Guzmán, T. Hägglund, K. Soltesz, “A Practical Guide to PID Controller Implementation,” arXiv:2604.15918 [eess.SY], 2026. https://arxiv.org/abs/2604.15918 ↩